よくcsvファイル中身をSQL Serverに挿入したりすることがあるが、普段はpythonのcsvモジュールを使ってcsvファイルを読み込み、dictに変換してSQL ServerにINSERTしたりしていた。(もっといい方法があるかも知れないが...)
恥ずかしいことに、今更ながらpandasを使ったcsvファイル扱いがめちゃくちゃ楽ということに気づいたのでメモ。データ分析がっつりやる人にとっては当たり前なんだろうな...
pandasとは
pandasとは、データ分析を支援するライブラリの一つで、表データや行列を扱うことができる。 またSQLに似た操作関数が用意されているので、SQLを触ったことあるとわりととっつきやすいかも。
今回はpandasを使ったDataFrameの操作、SQL Serverとのデータのやりとりを書いていきたいと思う。
pandasを使ってDataFrameにcsvデータを挿入
DataFrameとは
2次元のデータ構造を表すpandasのオブジェクト。行、列の名前を持すことができたり、表に対していろいろな操作(追加、削除、抽出、ソート、etc...)などを行うことができる。
まずはpandasをpip経由でインストール
$ pip install pandas
サンプルとなるcsvファイルを用意する(sample.csv)
name,price,quantity apple,100,3 strawberry,110,5 banana,90,2 grape,150,6 orange,200,3 peach,130,2 lemon,180,4
pd.read_csv()メソッドでcsvの中身を読み込んで、DataFrameに挿入
import pandas as pd df = pd.read_csv('sample.csv') print(df)
これでプログラムを実行させると以下のようにDataFrameの中身を表示することができる。
$ python sample.py
name price quantity
0 apple 100 3
1 strawberry 110 5
2 banana 90 2
3 grape 150 6
4 orange 200 3
5 peach 130 2
6 lemon 180 4
csvファイルを読み込む際のさまざまなオプションについてはこちらがかなり参考になった。
このDataFrameオブジェクトに対して、条件付きで指定した行だけを抽出したり、ソートしたりといろいろできる。
例えばpriceの値を元に昇順にソートしたい場合に
import pandas as pd df = pd.read_csv('sample.csv') print(df.sort_values(by='price'))
sort_values()メソッドを使うと以下のように行を並び替えることができる。
$ python sample.py
name price quantity
2 banana 90 2
0 apple 100 3
1 strawberry 110 5
5 peach 130 2
3 grape 150 6
6 lemon 180 4
4 orange 200 3
SQL ServerのテーブルからpandasのDataFrameにデータを挿入
今回SQL ServerはAzure SQL Databaseを使ってテーブル内のデータをpandasのDataFrameに挿入していく。
サンプルとして以下のようなテーブルをデータベースに作成し、サンプルデータをINSERT
CREATE TABLE [dbo].[sample] ( [name] VARCHAR(20) NOT NULL, [price] INT NOT NULL, [quantity] INT NOT NULL, ) INSERT INTO [dbo].[sample] (name, price, quantity) VALUES ('apple', 100, 3), ('strawberry', 110, 5), ('banana', 90, 2), ('grape', 150, 6), ('orange', 200, 3), ('peach', 130, 2), ('lemon', 180,4)
SQL Serverに接続するためにpythonでODBC接続を行うことができるpyodbcモジュールをpip経由でインストール
pip install pyodbc
pd.read_sql()メソッドを使用し、SELECT文に対する結果をDataFrameに挿入
import pyodbc import pandas as pd server = '<ホスト名>' database = '<データベース名>' username = '<ユーザー名>' password = '<パスワード>' cnxn = pyodbc.connect('DRIVER={ODBC Driver 17 for SQL Server};SERVER='+server+';DATABASE='+database+';UID='+username+';PWD='+ password) cursor = cnxn.cursor() query = "SELECT name, price, quantity FROM [dbo].[sample]" df = pd.read_sql(query, cnxn) print(df)
プログラムを実行させるとSQLの結果をDataFrameオブジェクトとして表示させることができる。
$ python sample.py
name price quantity
0 apple 100 3
1 strawberry 110 5
2 banana 90 2
3 grape 150 6
4 orange 200 3
5 peach 130 2
6 lemon 180 4
pandasのDataFrameからSQL Serverのテーブルにデータを挿入
今度は逆にDataFrameに入っているデータをSQL Serverに挿入していく。
サンプルとなるcsvファイルを用意する(department.csv)
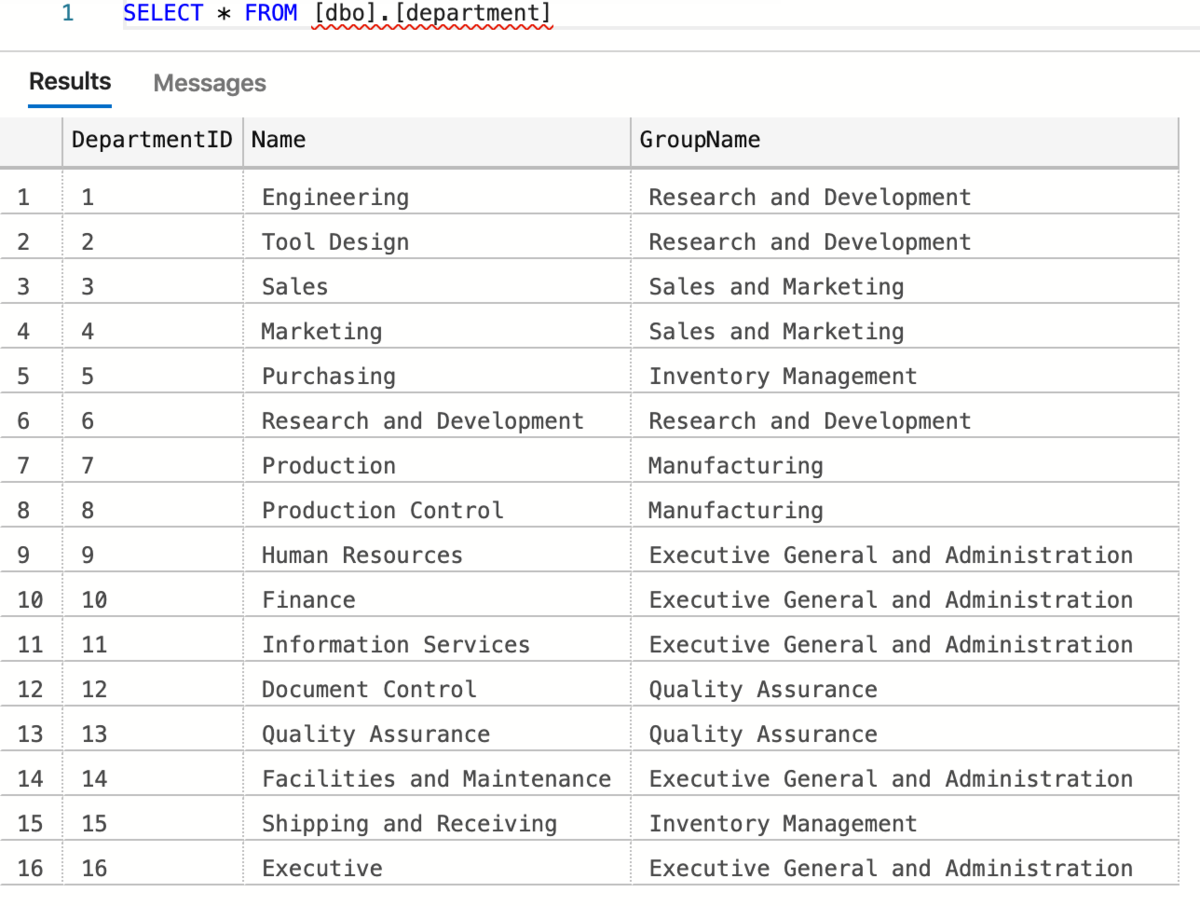
DepartmentID,Name,GroupName, 1,Engineering,Research and Development, 2,Tool Design,Research and Development, 3,Sales,Sales and Marketing, 4,Marketing,Sales and Marketing, 5,Purchasing,Inventory Management, 6,Research and Development,Research and Development, 7,Production,Manufacturing, 8,Production Control,Manufacturing, 9,Human Resources,Executive General and Administration, 10,Finance,Executive General and Administration, 11,Information Services,Executive General and Administration, 12,Document Control,Quality Assurance, 13,Quality Assurance,Quality Assurance, 14,Facilities and Maintenance,Executive General and Administration, 15,Shipping and Receiving,Inventory Management, 16,Executive,Executive General and Administration
データ挿入先のテーブルを作成
CREATE TABLE [dbo].[department]( [DepartmentID] INT NOT NULL, [Name] VARCHAR(20) NOT NULL, [GroupName] VARCHAR(50) NOT NULL )
pd.read_csv()メソッドを使ってcsvファイルを読み込んでDataFrameへ挿入
iterrows()メソッドでDataFrameオブジェクトから一行ずつ取り出して、データベースへINSERTする
DataFrameオブジェクトのイテレーション周りの処理はこちらが参考になった。
import pyodbc import pandas as pd server = '<ホスト名>' database = '<データベース名>' username = '<ユーザー名>' password = '<パスワード>' cnxn = pyodbc.connect('DRIVER={ODBC Driver 17 for SQL Server};SERVER='+server + ';DATABASE='+database+';UID='+username+';PWD=' + password) cursor = cnxn.cursor() df = pd.read_csv('department.csv') for index, row in df.iterrows(): cursor.execute("INSERT INTO [dbo].[department] (DepartmentID,Name,GroupName) values(?,?,?)", row.DepartmentID, row.Name, row.GroupName) cnxn.commit() cursor.close()
csvファイルの中身がデータベースに格納されているのがわかる。
まとめ
pandasを使うことで簡単にcsvデータをデータベースに挿入できたり、取得できるのでpythonを使ったデータ分析をするのであればぜひ押さえておきたい。 numpyと組み合わせることで、さらに威力を増すようなので、次の機会に試して深掘りしていく。